
📢 공지합니다
이 게시글은 메인 페이지에 항상 고정되어 표시됩니다.
안녕하세요.
이번 시간에는 인덱스(Index) 에 대해 확실히 정복하고자 한다.
단순히 “검색을 빠르게 해주는 기능”으로만 알고 있었다면, 오늘을 기점으로 인덱스의 구조, 동작 원리, 선택 기준까지 명확히 이해하게 될 것이다.
핵심은 “왜 이 인덱스를 써야 하는가”를 스스로 설명할 수 있는 수준까지 도달하는 것이다.
그럼 지금부터 인덱스의 세계로 함께 들어가보자.
https://balhae.tistory.com/335
[9oormthon 제주 버스 알림콜] 리메이크 및 조회 성능 최적화 하기
https://balhae.tistory.com/219 🍊구름톤(9oormthon) 11기 대상 후기📝 지원 동기와 과정대학교 4학년, 졸업을 앞둔 시점에서 문득 돌아보니 지금까지 만든 프로젝트들이 너무 의미없게 느껴졌습니다. 진
balhae.tistory.com
지난 제주 버스 알림콜 프로젝트에서 조회 성능을 최적화하는 과정에서 인덱스에 대해 얕게 공부해 본 적이 있다.
그렇다면 인덱스란 무엇일까?
인덱스(Index)는 말 그대로 ‘색인’ 또는 ‘목차’를 의미한다.
책에서 원하는 내용을 빠르게 찾기 위해 목차를 보는 것처럼, 데이터베이스에서도 원하는 데이터를 더 효율적으로 찾기 위해 인덱스를 사용한다.
그렇다면 인덱스는 왜 도입되었을까?
그 이유부터 차근히 살펴보자.
| fisrt_name | age |
| 김씨 | 15 |
| 이씨 | 30 |
| 박씨 | 25 |
| 김씨 | 20 |
| 이씨 | 10 |
위의 그림과 같이 people 테이블이 있다고 가정하자.
이 테이블에서 age = 20인 데이터를 찾으려면
SELECT * FROM people WHERE age = 20;
이라는 쿼리를 실행해야 한다.
하지만 이때 컴퓨터는 age가 20인 행을 찾기 위해 모든 데이터를 처음부터 끝까지 하나씩 확인해야 한다.
만약 행이 1억 개라면, 1억 번을 모두 확인해야 하는 셈이다.
이 방식이 바로 풀 테이블 스캔(Full Table Scan)이다.
풀 테이블 스캔은 데이터를 순차적으로 접근하기 때문에 오히려 작은 테이블에서는 효율적일 수 있다.
또한 적용 가능한 인덱스가 없거나, 인덱스를 적용하더라도 범위가 너무 넓어 성능 이점이 적을 때에도 사용된다.
즉, 비용 대비 효과가 낮을 때 풀 테이블 스캔을 수행하는 것이다.
그렇다면 컴퓨터가 데이터를 더 빠르고 효율적으로 찾기 위해 도입된 것이 바로 인덱스(Index)다.
인덱스를 이해하기 쉽게 예를 들어보자.
숫자 1부터 100까지 중에서 A가 생각한 숫자를 B와 C가 맞혀야 한다고 하자.
이처럼 인덱스는 데이터를 정렬한 후, 이진 탐색(Binary Search)처럼 빠르게 접근할 수 있도록 도와준다.
즉, 인덱스를 age 컬럼에 적용하면
age 값을 정렬된 상태로 복사해 별도의 구조(B+Tree 등)로 저장한다.
이를 통해 DB는 정렬된 사본(인덱스)을 통해 빠르게 특정 값을 찾고,
그 인덱스가 가리키는 원본 데이터(테이블 레코드)에 접근하게 된다.
정리하자면,
인덱스란 정렬된 데이터의 사본을 유지하여, 원하는 값을 훨씬 빠르게 찾을 수 있게 하는 기술이다.
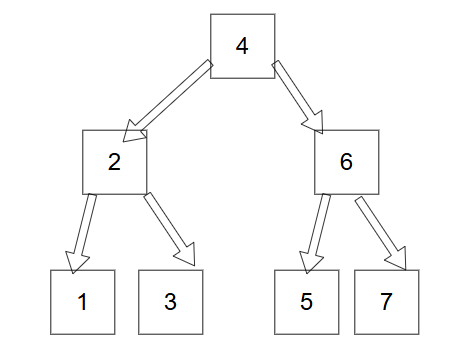
인덱스는 Array나 Linked List처럼 단순히 순차적으로 정렬된 구조가 아니라, 트리(Tree) 형태로 정렬된 구조를 가진다.
이때 사용되는 방식이 바로 이진 탐색 트리(Binary Search Tree) 구조이며, 탐색의 시간 복잡도는 O(log N) 수준으로 빠르다.
반면, 인덱스가 없을 경우에는 O(N) 시간이 걸리게 된다.
즉, 이진 탐색 트리 기반의 트리 구조가 기본적인 테이블 인덱스의 핵심 원리이다.

이때 노드를 하나씩만 배치하는 것이 아니라, 두 개 이상씩 묶어서 배치하는 방식을 사용하면 이것이 바로 B-Tree 구조이다.
즉, 이러한 방식으로 구성하면 1부터 13까지의 데이터를 효율적으로 탐색할 수 있으며,
앞서 살펴본 이진 탐색 트리(Binary Search Tree) 방식에서는 1부터 7까지만 처리할 수 있었던 것과 비교해
더 많은 데이터를 한 번에 관리하고 탐색 효율을 높일 수 있다.

위 그림처럼 가이드라인이 제공되어 탐색이 훨씬 용이해진다.
이때 B-Tree와의 가장 큰 차이점은, 단순히 가이드라인만 있는 것이 아니라 하위 노드들이 서로 연결(Linked)되어 있다는 점이다.
즉, 노드 간 이동이 훨씬 간단하며, 특히 범위 검색(Range Scan)에 매우 효율적이다.
예를 들어, ‘나이가 4부터 8까지인 데이터’를 찾는 경우를 보자.
B-Tree에서는 각 값을 찾기 위해 매번 노드를 타고 내려가야 하지만,
B+Tree에서는 한 번 4를 찾은 뒤, 연결된 노드를 따라 순차적으로 이동하기만 하면 된다.
이러한 이유로 최근 대부분의 데이터베이스는 인덱스를 B+Tree 구조로 구현하고 있다.
--
즉, 정리하자면 인덱스가 없는 경우에는 테이블에 존재하는 모든 데이터를 전부 탐색(Full Table Scan) 해야 하므로
검색 속도가 매우 느리다.
반면, 인덱스가 존재하는 경우에는 트리 구조를 따라 몇 번의 탐색만으로 원하는 데이터를 빠르게 찾을 수 있다.
또한 인덱스에는 원본 테이블의 행 주소(Row Address) 가 함께 저장되어 있어,
해당 주소를 참조함으로써 실제 테이블의 행을 효율적으로 반환할 수 있다.
결과적으로, 인덱스는 검색 속도를 획기적으로 향상시키는 핵심 구조라고 할 수 있다.
원본 테이블
| id | 강사 | 출신 대학 |
| 1 | 김을용 | 서울대 |
| 2 | 박덕팔 | 연세대 |
| 3 | 이상구 | 고려대 |
Index1
| 강사 |
| 김을용 |
| 박덕팔 |
| 이상구 |
| 출신 대학 |
| 고려대 |
| 서울대 |
| 연세대 |
인덱스는 특정 컬럼을 복사해 정렬해 두는 구조이기 때문에,
본래 테이블 외에도 위와 같이 추가적인 저장 공간을 차지한다.
따라서 검색에 사용되지 않는 컬럼에 불필요한 인덱스를 생성하는 것은 비효율적이다.
또한 인덱스는 조회 속도를 빠르게 해주는 대신,
데이터를 삽입(INSERT)·수정(UPDATE)·삭제(DELETE) 할 때마다
인덱스도 함께 갱신되어야 한다.
따라서 쓰기 작업이 잦은 테이블에서는 오버헤드가 커지고, 성능이 저하될 수 있다.
클러스터드 인덱스(Clustered Index) 는 일반적으로 PRIMARY KEY로 선언된 컬럼에 자동 적용된다.
보조 인덱스(Non-clustered Index)처럼 별도로 생성되는 구조가 아니라, 테이블 자체의 물리적 데이터가 인덱스 순서에 따라 정렬되는 방식이다.
즉, 테이블 자체가 인덱스 구조로 저장되는 형태라고 볼 수 있다.
일반적으로 인덱스는 하나의 데이터베이스 객체로서 약 10% 정도의 추가 저장 공간을 필요로 한다.
새로운 데이터를 삽입할 때 페이지(Page) 내부에 여유 공간이 없으면,
DB는 공간을 나누어 저장하기 위해 페이지 분할(Page Split) 을 수행한다.
이 과정은 디스크 I/O 증가 및 성능 저하로 이어질 수 있다.
또한 DELETE 작업 시 인덱스 데이터는 실제로 삭제되지 않고 ‘사용 안 함’ 표시만 되며,
UPDATE는 내부적으로 DELETE + INSERT 방식으로 처리된다.
이러한 동작이 반복되면 인덱스의 조각화(Fragmentation) 가 심해지고,
결과적으로 쿼리 성능이 점차 떨어지게 된다.
정리하자면, 인덱스는 조회 성능 향상에는 탁월하지만,
저장 공간 증가와 쓰기 성능 저하라는 대가를 수반한다.
따라서 읽기와 쓰기 비율을 고려한 인덱스 설계가 중요하다.
CREATE TABLE member (
id INT PRIMARY KEY, -- 클러스터링 인덱스
name VARCHAR(255),
email VARCHAR(255) UNIQUE -- 논-클러스터링 인덱스
);
보조 인덱스(Non-Clustered Index) 는 우리가 앞서 살펴본 인덱스 구조를 의미한다.
즉, 클러스터드 인덱스와 달리 테이블의 물리적 순서와는 별개로 관리되는 인덱스이다.
이 인덱스는 데이터 행의 주소(Row Address) 를 별도로 가지고 있어, 인덱스를 통해 해당 주소를 찾아가 실제 데이터를 조회하게 된다.
또한, UNIQUE 제약 조건(Constraint) 을 설정하면 해당 컬럼에 대해 자동으로 보조 인덱스가 생성된다.
이로써 중복된 값을 방지함과 동시에,해당 컬럼을 기준으로 한 검색 성능이 향상된다.
-- 보조 인덱스 생성 3가지 방법 정리
-- 방법 1: 제약조건으로 UNIQUE 인덱스 생성
ALTER TABLE member
ADD CONSTRAINT unq_name UNIQUE (name);
-- 방법 2: UNIQUE INDEX 직접 생성
CREATE UNIQUE INDEX unq_idx_name
ON member (name);
-- 방법 3: 일반 INDEX (중복 허용)
CREATE INDEX idx_name
ON member (name);
추가로, 중복을 방지하고 싶다면 UNIQUE 제약 조건을 사용하면 된다.
데이터베이스에서는 일반적으로 기본 인덱스(Default Index) 가 자동으로 생성되지만,
중복을 허용하지 않으려면 UNIQUE INDEX를 명시적으로 생성하면 된다.
즉,
이렇게 선택적으로 설정할 수 있다.

실제 보조 인덱스 구조다.
추가로, 클러스터드 인덱스와 논클러스터드 인덱스를 구성할 때는 실제로 보조 인덱스(Non-Clustered Index) 에는 데이터 페이지의 물리적 주소값이 직접 저장되는 것이 아니라, 해당 행을 식별할 수 있는 클러스터드 인덱스의 키 값(ID 컬럼 값) 이 저장된다.
id, 이름, 그룹, 이메일, 성별, 주민번호, 나이 등등
이처럼 인덱스 구조가 복잡하다 보니, 어떤 컬럼에 인덱스를 적용해야 할지 고민이 생긴다.
앞서 언급했듯이, 그 해답은 바로 카디널리티(Cardinality) 에 있다.
즉, 카디널리티가 높은 컬럼, 다시 말해 중복되는 값이 적은 컬럼에 인덱스를 적용하는 것이 효율적이다.
이런 컬럼일수록 인덱스를 통한 데이터 선별 효과가 커지고, 결과적으로 검색 성능 향상에 가장 큰 영향을 준다.
| 12 | 10 | 2 | 2 | 12 | 5 | 8 |
| id | 이름 | 그룹 | 성별 | 이메일 | 사는 지역 | 나이 |
| 1 | 승호 | BE | 남 | test1@gmail.com | 성남 | 23 |
| 2 | 디코 | BE | 여 | test2@gmail.com | 서울 | 21 |
| 3 | 세현 | BE | 남 | test3@gmail.com | 수원 | 23 |
| 4 | 유성 | BE | 남 | test4@gmail.com | 서울 | 24 |
| 5 | 용현 | FE | 여 | test5@gmail.com | 서울 | 23 |
| 6 | 민수 | BE | 남 | test6@gmail.com | 남양주 | 24 |
| 7 | 관우 | FE | 남 | test7@gmail.com | 서울 | 24 |
| 8 | 경진 | BE | 여 | test8@gmail.com | 서울 | 23 |
| 9 | 지현 | BE | 남 | test9@gmail.com | 서울 | 24 |
| 10 | 건호 | BE | 남 | test10@gmail.com | 서울 | 23 |
| 11 | 재민 | BE | 여 | test11@gmail.com | 인천 | 24 |
| 12 | 원녕 | BE | 여 | test12@gmail.com | 서울 | 26 |
예를 들어, ID, 이메일, 주민등록번호와 같은 컬럼이 대표적인 카디널리티가 높은 컬럼이다.
이러한 컬럼들은 값의 중복이 거의 없기 때문에 인덱스를 적용하기에 가장 적합하다.
또한, 인덱스에는 복합 인덱스(Composite Index) 라는 개념도 있다.
복합 인덱스는 여러 컬럼을 결합하여 하나의 인덱스로 구성한 형태로, 왼쪽(앞쪽) 컬럼부터 순서대로 조건에 사용할 때만 효율적으로 동작한다.
즉, 인덱스의 선두 컬럼(Leading Column) 을 기준으로 쿼리를 작성해야 최적의 인덱스 효과를 얻을 수 있다.
CREATE INDEX idx_user ON user (age, name, city);
즉, 해당 테이블의 인덱스는 age → name → city 순으로 정렬되어 있다.
WHERE age = 25
WHERE age = 25 AND name = '승호'
WHERE age = 25 AND name = '승호' AND city = '서울'
이렇게는 where절이 가능하지만
WHERE name = '승호' -- ❌ age가 빠져서 불가능
WHERE city = '서울' -- ❌ age, name 다 빠짐
WHERE name = '승호' AND city = '서울' -- ❌ age가 없으므로 불가능
위와 같이는 안된다.
즉, 인덱스는 항상 맨 왼쪽 컬럼부터 차례로 사용될 때만 의미가 있다.
인덱스는 검색 범위를 좁히는 구조이기 때문에, 먼저 필터링되는 컬럼의 값이 다양할수록 인덱스 탐색 범위를 빠르게 줄일 수 있다.
즉 값이 다양할수록(중복이 적을수록) 앞에 둔다.
| 컬럼 | 서로 다른 값 | 개수 비교 |
| age | 100개 (20~60살 등) | 다양성 중간 |
| name | 50,000개 | 다양성 높음 |
| city | 10개 | 다양성 낮음 |
이 경우 name을 앞에 두는 것이 효율적. 👉 (name, age, city)
하지만, 대부분의 쿼리가 age 기준으로 시작한다면 → (age, name, city)도 합리적 선택이 될 수 있다.
인덱스는 WHERE 절의 조건 컬럼을 기준으로 탐색한다.
따라서 가장 자주 필터링되는 컬럼을 인덱스의 앞부분에 두는 게 핵심이다.
즉 WHERE 조건에 자주 등장하는 컬럼을 앞에 둔다.
SELECT * FROM user WHERE age = 25 AND name = '승호';
등호(=) 조건은 인덱스를 끝까지 사용할 수 있지만,
범위 조건(<, >, BETWEEN, LIKE)은 그 지점에서 탐색이 끊긴다.
즉 등호(=) 조건 컬럼은 앞에, 범위(<, >, LIKE)는 뒤쪽에 둔다.
-- 등호 조건만 있을 때
SELECT * FROM user
WHERE age = 25 AND name = '승호' AND city = '서울';
→ 인덱스 (age, name, city) 전부 사용
-- LIKE(범위 조건) 포함
SELECT * FROM user
WHERE age = 25 AND name LIKE '김%' AND city = '서울';
→ age까지만 완전 탐색 가능
→ name에서 탐색이 끊기므로 city는 인덱스 미사용 ❌
그래서 등호 조건 컬럼을 앞에, 범위 조건 컬럼을 뒤로 두는 게 원칙이다.
인덱스는 이미 정렬된 구조이기 때문에, WHERE 조건 이후의 ORDER BY 컬럼이 인덱스 순서와 일치하면
DB가 추가 정렬(filesort) 을 하지 않아도 된다.
즉 정렬이나 그룹화에 사용되는 컬럼은 뒤쪽에 둔다.
SELECT * FROM user
WHERE age = 25
ORDER BY name, city;→ 인덱스 (age, name, city) 와 정렬 순서가 동일하므로
→ WHERE + ORDER BY를 모두 인덱스로 처리 가능
SELECT * FROM user
WHERE age = 25
ORDER BY city, name;→ 인덱스 순서와 다르기 때문에 filesort 발생 ❌
그럼 아래 문제를 풀어보자
Book 테이블에
category 칼럼
author 칼럼(작가/식별성 높음/ 동명이인 가능)가 있다.
Book 테이블은 500만개
카테고리는 총 20개로 가정합니다
select * from book where category = ? and author = ?
인덱스
A (category)
B (author)
C (category, author)
D (author, category)
이 쿼리에 대한 인덱스 선택의 문제이다.
1. 해당 쿼리 기준으로 C(category, author)와 D(author, category)의 인덱스 동작의 차이를 설명하세요.
정답:
C는 category로 먼저 좁히고 author로 필터링한다.
D는 author로 먼저 좁히기 때문에 선택도가 높아 더 효율적이다.
두 쿼리 모두 인덱스 시크 가능하지만, 보통 D가 더 빠르
2. 해당 쿼리 기준 가장 느린 인덱스를 선택하세요.
정답:
A(category). 카디널리티가 낮아 한 category당 수십만 건을 스캔해야 한다.
3. 해당 쿼리 기준 B (author)와 D (author, category) 인덱스 동작 차이를 설명하세요.
정답:
B는 author까지만 인덱스로 찾고 category는 테이블에서 비교한다.
D는 두 조건을 모두 인덱스로 처리해 범위가 훨씬 좁다.
4. select * from book category = ? and author like '%단어%' 로 바뀐다면 가장 빠른 인덱스를 선택하세요.
정답:
C(category, author).
category로 먼저 좁히고 LIKE 검색을 그 범위 내에서 수행할 수 있다.
5. select * from book author like '%단어%' 로 바뀐다면 가장 빠른 인덱스를 선택하세요.
정답:
B(author).
LIKE 앞에 %가 있어 전체 스캔이지만, 단일 인덱스라 D보다 효율적이다.
6. select * from book where author = ? 쿼리에서 C (category, author) 인덱스 동작 방식을 설명하세요.
정답:
선두 컬럼(category)이 빠져 탐색이 불가능하다.
결국 전체 인덱스를 스캔해야 한다.
| Web Server와 WAS의 차이와 웹 서비스 구조 (0) | 2025.06.24 |
|---|---|
| @Transactional의 역사 (0) | 2025.06.23 |
| 멀티스레드 환경에서 동시성 이슈 (0) | 2025.06.23 |
| 데이터베이스의 지식 (0) | 2025.06.11 |
| N+1문제 (1) | 2025.06.10 |