

📢 공지합니다
이 게시글은 메인 페이지에 항상 고정되어 표시됩니다.
이번 시간에는 KoBart 모델을 활용해서 요약모델을 만드는 법을 진행하도록 하겠다.
https://github.com/seujung/KoBART-summarization
GitHub - seujung/KoBART-summarization: Summarization module based on KoBART
Summarization module based on KoBART. Contribute to seujung/KoBART-summarization development by creating an account on GitHub.
github.com
- 우리의 목표는 위 깃허브에서 KoBart의 요약 모델을 가져옵니다.
- 그 후 우리가 직접 AI Hub에서 훈련데이터와 테스트 데이터를 가져옵니다.
- KoBart 모델을 기반으로 훈련을 시켜 정확도를 향상시킵니다.
- 우리가 훈련시킨 모델을 최종적으로 사용을 합니다.
import torch
from transformers import PreTrainedTokenizerFast, BartForConditionalGeneration, BartModel
tokenizer = PreTrainedTokenizerFast.from_pretrained('digit82/kobart-summarization')
model = BartForConditionalGeneration.from_pretrained('digit82/kobart-summarization')
text = """
1일 오후 9시까지 최소 20만3220명이 코로나19에 신규 확진됐다. 또다시 동시간대 최다 기록으로, 사상 처음 20만명대에 진입했다.
방역 당국과 서울시 등 각 지방자치단체에 따르면 이날 0시부터 오후 9시까지 전국 신규 확진자는 총 20만3220명으로 집계됐다.
국내 신규 확진자 수가 20만명대를 넘어선 것은 이번이 처음이다.
동시간대 최다 기록은 지난 23일 오후 9시 기준 16만1389명이었는데, 이를 무려 4만1831명이나 웃돌았다. 전날 같은 시간 기록한 13만3481명보다도 6만9739명 많다.
확진자 폭증은 3시간 전인 오후 6시 집계에서도 예견됐다.
오후 6시까지 최소 17만8603명이 신규 확진돼 동시간대 최다 기록(24일 13만8419명)을 갈아치운 데 이어 이미 직전 0시 기준 역대 최다 기록도 넘어섰다. 역대 최다 기록은 지난 23일 0시 기준 17만1451명이었다.
17개 지자체별로 보면 서울 4만6938명, 경기 6만7322명, 인천 1만985명 등 수도권이 12만5245명으로 전체의 61.6%를 차지했다. 서울과 경기는 모두 동시간대 기준 최다로, 처음으로 각각 4만명과 6만명을 넘어섰다.
비수도권에서는 7만7975명(38.3%)이 발생했다. 제주를 제외한 나머지 지역에서 모두 동시간대 최다를 새로 썼다.
부산 1만890명, 경남 9909명, 대구 6900명, 경북 6977명, 충남 5900명, 대전 5292명, 전북 5150명, 울산 5141명, 광주 5130명, 전남 4996명, 강원 4932명, 충북 3845명, 제주 1513명, 세종 1400명이다.
집계를 마감하는 자정까지 시간이 남아있는 만큼 2일 0시 기준으로 발표될 신규 확진자 수는 이보다 더 늘어날 수 있다. 이에 따라 최종 집계되는 확진자 수는 21만명 안팎을 기록할 수 있을 전망이다.
한편 전날 하루 선별진료소에서 이뤄진 검사는 70만8763건으로 검사 양성률은 40.5%다. 양성률이 40%를 넘은 것은 이번이 처음이다. 확산세가 계속 거세질 수 있다는 얘기다.
이날 0시 기준 신규 확진자는 13만8993명이었다. 이틀 연속 13만명대를 이어갔다. """
text = text.replace('\n', ' ')
raw_input_ids = tokenizer.encode(text)
input_ids = [tokenizer.bos_token_id] + raw_input_ids + [tokenizer.eos_token_id]
summary_ids = model.generate(torch.tensor([input_ids]), num_beams=4, max_length=512, eos_token_id=1)
decode = tokenizer.decode(summary_ids.squeeze().tolist(), skip_special_tokens=True)
print(decode)
깃허브 리드미에 명시되어있는 코드를 가져와서 실행을 시키면 그 결과 깃허브와 동일하게 요약문이 잘 나오는 것을 확인할 수 있습니다.
참고로 torch 및 transformers는 pip install을 활용해서 설치를 해야된다. 버전이 파이썬마다 달라 설치가 안될 수 있습니다ㅜㅜㅜ
필자는 파이참을 활용해서 만들었습니다!!
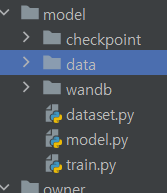
필자는 위와같이 구조를 설정해놓습니다.
위 링크 KoBart 깃허브에서 dataset, model, train 코드를 가져와 다음과 같이 진행을 해줍니다.

data 파일에는 AIHub에서 가져온 데이터를 csv를 만들어 tsv로 변환한뒤 위와 같이 저장을 하면 됩니다!
참고로 위 사진에서는 csv는 무시하셔도 됩니다!!

훈련데이터 및 테스트 데이터 파일 구조는 위와 같이 2개의 컬럼으로 구성을 해야됩니다.
즉 컬럼명도 위와 같이 동일하게 작성을 해야합니다!
일단 필자는 훈련데이터를 뉴스로 설정했고 테스트데이터는 논문으로 설정해 놓았습니다.
테스트 데이터를 굳이 설정하는 이유는 모델의 정확도를 조금이나마 향상시키기 위해서입니다!

위 사진은 dataset.py 코드인데 위와 같이 tsv에 저장된 컬럼명과 동일하게 작성을 해야됩니다!!

다음은 train.py 코드입니다. 테스트 및 훈련 데이터 구조를 위와 같이 설정을 해두어야 됩니다!

노트북이거나 PC에 gpu가 없을 경우 위 사진 train.py 코드에서 default 값을 cpu로 바꿔줍니다.
물론 훈련하는데에 있어서 지장은 없지만 시간이 꽤 오래걸립니다.... gpu 사세여 ㅜㅜㅜ
저는 12시간 걸림...
훈련하기전에 wandb 설정을 해두어야 됩니다.
 |
 |
회원 가입을 하면 API Key를 줍니다. 그 후 터미널에서 wandb login을 실행하고 아이디 및 비밀번호를 입력하면
정상적으로 로그인 되었다고 뜹니다.
참고로 wandb에서 위 사진들과 같이 프로젝트를 하나 만듭니다. 저는 news-summ이라는 프로젝트를 만들어 위와 같이 작성을 했습니다.
물론 이 작업은 훈련하는데에 있어서 필요없습니다. 그래서 코드를 빼주셔도 상관없는데 시각적으로 훈련 결과를 확인하기 위해서는 좋은 작업이라고 생각해 모두들 설정해주시면 큰 도움 될거같습니다~~!!
train.py 파일로 들어가 실행을 눌러줍니다.

그럼 터미널에서 훈련중이라고 위 사진과 같이 뜹니다. 시간이 오래 걸립니다.....
필자는 에포크를 10으로 설정을 해놓았습니다. 에포크 설정은 train.py에 들어가면 있습니다.

그럼 에포크가 될때마다 위 사진과 같이 저장이 됩니다.
최종적으로 마무리 될때 last.ckpt 라고 저장이됩니다!! 참고로 필자가 계속 훈련해서 last -v1 등등은 무시해도 돼요!!
from transformers import PreTrainedTokenizerFast, BartForConditionalGeneration, BartModel
from model import KoBARTConditionalGeneration
# 저장된 모델 파일 경로
model_path = "C:\\Users\\chltm\\PycharmProjects\\amcn_AI\\summary\\model\\checkpoint\\last.ckpt"
# 모델 및 토크나이저 로드
tokenizer = PreTrainedTokenizerFast.from_pretrained('digit82/kobart-summarization')
loaded_model = KoBARTConditionalGeneration.load_from_checkpoint(model_path)
# 텍스트 요약 생성
input_text = """
1일 오후 9시까지 최소 20만3220명이 코로나19에 신규 확진됐다. 또다시 동시간대 최다 기록으로, 사상 처음 20만명대에 진입했다.
방역 당국과 서울시 등 각 지방자치단체에 따르면 이날 0시부터 오후 9시까지 전국 신규 확진자는 총 20만3220명으로 집계됐다.
국내 신규 확진자 수가 20만명대를 넘어선 것은 이번이 처음이다.
동시간대 최다 기록은 지난 23일 오후 9시 기준 16만1389명이었는데, 이를 무려 4만1831명이나 웃돌았다. 전날 같은 시간 기록한 13만3481명보다도 6만9739명 많다.
확진자 폭증은 3시간 전인 오후 6시 집계에서도 예견됐다.
오후 6시까지 최소 17만8603명이 신규 확진돼 동시간대 최다 기록(24일 13만8419명)을 갈아치운 데 이어 이미 직전 0시 기준 역대 최다 기록도 넘어섰다. 역대 최다 기록은 지난 23일 0시 기준 17만1451명이었다.
17개 지자체별로 보면 서울 4만6938명, 경기 6만7322명, 인천 1만985명 등 수도권이 12만5245명으로 전체의 61.6%를 차지했다. 서울과 경기는 모두 동시간대 기준 최다로, 처음으로 각각 4만명과 6만명을 넘어섰다.
비수도권에서는 7만7975명(38.3%)이 발생했다. 제주를 제외한 나머지 지역에서 모두 동시간대 최다를 새로 썼다.
부산 1만890명, 경남 9909명, 대구 6900명, 경북 6977명, 충남 5900명, 대전 5292명, 전북 5150명, 울산 5141명, 광주 5130명, 전남 4996명, 강원 4932명, 충북 3845명, 제주 1513명, 세종 1400명이다.
집계를 마감하는 자정까지 시간이 남아있는 만큼 2일 0시 기준으로 발표될 신규 확진자 수는 이보다 더 늘어날 수 있다. 이에 따라 최종 집계되는 확진자 수는 21만명 안팎을 기록할 수 있을 전망이다.
한편 전날 하루 선별진료소에서 이뤄진 검사는 70만8763건으로 검사 양성률은 40.5%다. 양성률이 40%를 넘은 것은 이번이 처음이다. 확산세가 계속 거세질 수 있다는 얘기다.
이날 0시 기준 신규 확진자는 13만8993명이었다. 이틀 연속 13만명대를 이어갔다.
"""
summary_text = loaded_model.generate(input_text, tokenizer, num_beams=4, max_length=512, early_stopping=True)
print(summary_text)

그럼 이제 맨 위에 있는 코드와 동일하게 작성하고 모델을 불러오는 경로만 이전에 저장되었던 last.ckpt를 적용시켜준뒤
실행을 시킵니다!
그 결과!!


위 사진과 같이 이전 Kobart 원본 요약 모델이랑 필자가 훈련시킨 모델이랑 결과가 다른 것을 확인할 수 있습니다.


하지만.... 정확도에서는 훈련시킨 모델이 더 낮다고 뜹니다....... 무려 10점차이로 ㅜㅜㅜㅜ
왜일까요???? 지피티한테 물어보니

위와 같이 답변을 하네요.... 제 생각에는 데이터 품질이 별로인거 같아서 그런거 같습니다....
모르시는거 있으시면 물어봐주세요!!! 적극적으로 도와드릴게요!!
도움이 되셨다면 감사합니다!!
| 스프링 소셜 로그인 구현하기(네이버, 카카오, OAuth2.0) (0) | 2024.07.09 |
|---|---|
| 스프링과 파이썬 스크립트 연결(TTS 만들기) (0) | 2024.06.11 |
| 스프링과 Open AI DALL-E-3 API 연결 (0) | 2024.05.30 |
| 스프링 & AJAX를 활용한 실시간 메일 인증 (1) | 2024.05.15 |
| 스프링 메일 보내기 (네이버, 구글) (0) | 2024.05.07 |



